What is VMware Cloud Director Object Storage Extension? #
The VMware Cloud Director Object Storage Extension (OSE) allows VMware Cloud Providers who are using VMware Cloud Director to offer object storage services to their customers. The extension acts as middleware which is tightly integrated with VMware Cloud Director to abstract third-party S3 API compatible storage providers in a multi-tenant fashion. OSE runs externally to VMware Cloud Director and integrates through a UI plug-in, which shows either provider or tenant information, depending on the type of logged-in user.
OSE has a 1:1 relationship with VMware Cloud Director, which means that only one instance of OSE can be integrated with a single Cloud Director. OSE 2.1.1 is compatible with VMware Cloud Director version 10.0 and later and the Cloud Director Service.
An instance of VMware Cloud Director Object Storage Extension can work with a single instance of VMware Cloud Director or a single VMware Cloud Director server group.
Object Storage Extension can be connected to the following storage providers: Cloudian HyperStore, Dell EMC ECS, AWS S3, or another S3-compatible storage platform1. The provider can selectively enable VMware Cloud Director organizations to consume the service. The unique counterparts for organizations and users are created at the storage provider. The users authenticate to the service with VMware Cloud Director or S3 credentials and access it only through the UI plug-in. The provider can directly access the underlying storage appliance to set quotas or collect usage information for billing purposes.
Providers can switch between storage platforms with VMware Cloud Director Object Storage Extension but cannot use two different storage platforms simultaneously.
In addition to the storage platform that OSE will connect with Cloud Director, three or more (for high availability and scalability) RHEL/CentOS/Oracle Linux/Ubuntu/Debian/Photon VM nodes that run OSE, provided as an RPM or DEB package, are required. The number of the OSE VM nodes depends on the used S3 storage and the OSE use case. See for reference: Deployment Options. These VMs are essentially stateless and persist all their data in PostgreSQL DB version from 10. x to 12.x. This could be VMware Cloud Director external PostgreSQL DB (if available) or a dedicated database for Mware Cloud Director Object Storage Extension depending on the OSE use case.
VMware Cloud Director Object Storage Extension (OSE) enables Cloud Director tenant users to use object storage by native UI experience and support S3 clients to consume the object storage by S3 APIs.
To connect Cloud Director with the selected S3 object storage platform, OSE uses the following user mapping: • VMware Cloud Director service provider is mapped to an ECS/Cloudian admin user, or AWS management account. • VMware Cloud Director tenant is mapped to an ECS namespace, Cloudian group, or AWS org unit. • VMware Cloud Director user is mapped to an ECS/Cloudian user, or AWS IAM user.
Other S3-compatible storage can be connected to Cloud Director through the Object Storage Interoperability Service (OSIS).
Use Cases #
VMware Cloud Director natively provides Infrastructure as a Service (Iaas) by integrating with the underlying VMware vSphere platform. All native storage services such as storage for virtual machines, named (independent) disks, and catalog storage for virtual machine templates and media are using storage attached to vSphere ESXi hosts such as block storage, NFS, or VMware vSAN.
There is, however, the need for highly scalable, durable, and network-accessible storage that could be utilized by tenants or their workloads without the dependency on the vSphere layer. The VMware Cloud Director Object Storage Extension (OSE) provides access to the object storage either through VMware Cloud Director UI extension or via standardized S3 APIs. This allows existing applications to easily access this new type of storage for various use cases.
Storing Unstructured Data #
Through the VMware Cloud Director User Interface, users can create storage buckets and upload and tag unstructured files (objects) of various types.
These files can be easily accessed with Uniform Resource Locator (URL) links or directly previewed from the OSE plug-in. For protection, versioning and object lock can be applied to the S3 bucket objects. Archived objects in AWS S3 buckets can also be restored, which is basically changing their status from archived to frequently accessed objects to view their content. The objects of Cloudian buckets can also be replicated across data centers by setting up an org-level storage policy or changing it individually per a tenant.
Persistent Storage for Application #
Users can create application credentials with limited access to a specific bucket. This allows (stateless) applications running in VMware Cloud Director (or outside) to persist their content such as configurations, logs, or static data (web servers) into the object store. The application is using S3 API over the Internet to upload and retrieve object data.
Storing vApp Templates and Catalog #
Because of the close integration with VMware Cloud Director, VMware Cloud Director Object Storage Extension can directly capture and restore a user’s VMware Cloud Director vApps. Users can also share these vApps with other users. Thus, VMware Cloud Director Object Storage Extension provides an additional tier of storage for vApp templates that can be used, for example, for archiving old images.
Because of the close integration with VMware Cloud Director, VMware Cloud Director Object Storage Extension can directly capture and restore a user’s VMware Cloud Director vApps. Users can also share these vApps with other users. Thus, VMware Cloud Director Object Storage Extension provides an additional tier of storage for vApp templates that can be used, for example, for archiving old images.
An entire VMware Cloud Director catalog (consisting of vApp templates and media ISO images) can be captured from an existing Org VCD catalog or created from scratch by uploading an individual ISO and OVA files to VMware Cloud Director Object Storage Extension. Then, the catalog can be published, which allows any VMware Cloud Director organization (from any VMware Cloud Director instance) to subscribe to the catalog. As a result, this OSE functionality enables easy distribution of specific catalogs publicly or geographically across VMware Cloud Director instances.
Kubernetes Cluster Backup and Restore #
In OSE 2.1.1, Kubernetes cluster backups complement the storage of unstructured data, vApps, and catalogs. With the Kubernetes cluster protection, tenants can back up their critical Kubernetes clusters and restore the backups in case of accidental removal of namespaces or a Kubernetes upgrade failure. Tenants can also use the Kubernetes cluster backup to replicate the cluster for debugging, development and staging before rolling their app out in production.
Architecture #
OSE is a standalone server running on a Linux machine and multi-node deployment. It exposes SSL port 443 as the public endpoint. Both OSE UI plugins and S3 client applications connect to OSE APIs on this port. OSE supports S3-compliant XML APIs and Amazon Signature V4 authentication. It’s primarily compatible with any S3 compliant clients.
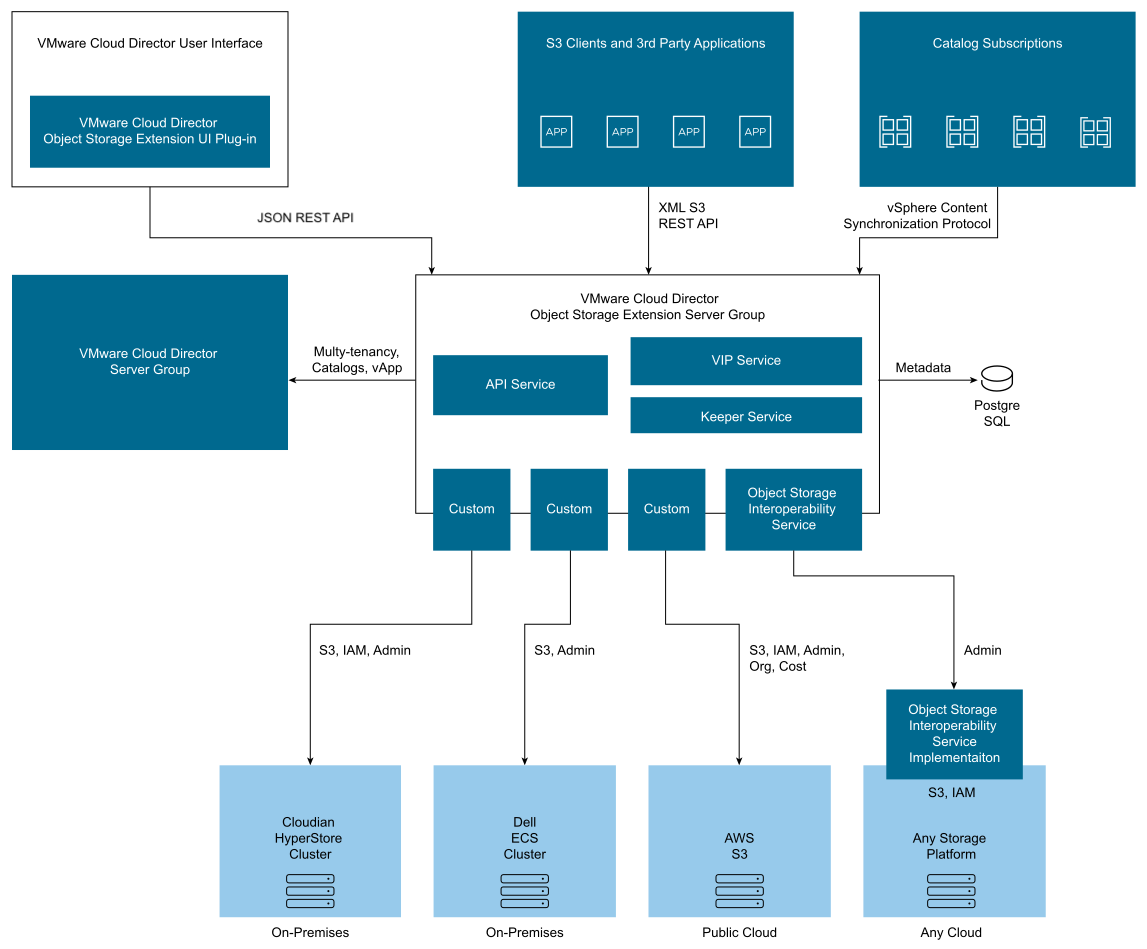
OSE connects to Cloud Director and the object storage cluster from the backend. OSE makes REST API calls to Cloud Director for tenant and user mapping for object storage. It also supports object storage-backed catalog contents and vApp backups. OSE connects to the object storage cluster for tenancy management and data transfer. Depending on the type of object storage cluster, there could be one port or multiple ports for the communication between OSE and the object storage cluster.
OSE uses S3 API to make queries to the underlying S3 storage vendor and user identity and access management service to map Cloud Director user types with those of the connected storage.
OSE also uses a PostgreSQL database to store metadata. All management data, bucket metadata, and object metadata are stored in the database. If your object storage solution is for internal use or a small business, you can consider re-using Cloud Director’s PostgreSQL appliance. For a standard deployment, you should consider deploying a standalone PostgreSQL server for OSE.
The bandwidth consumption between OSE and the object storage cluster is much higher than the communication between OSE and Cloud Director, so you should consider deploying OSE server nodes into the network with as little latency as the communication with the storage cluster.
OSE also makes REST API calls to VMware Cloud Analytics to send product usage data. This part of the OSE architecture comes into play only if the tenants agree with the VMware Customer Experience Improvement Program (CEIP) in Cloud Director UI to allow VMware to collect data for analysis.
OSE also uses a Kubernetes agent called Velero to backup and restore Kubernetes clusters on the underlying S3 storage. This OSE feature uses a deployer that enables the Cloud Director tenants to perform Helm operations to external Kubernetes clusters.
OSE Catalogs use vSphere catalog synchronization protocol to sync with the content of the Cloud Director Catalogs.
For vApps, OSE uses REST API to export vApps from Cloud Director to the underlying S3 storage.
Deployment Options #
Small Deployment #
Usage: Niche use cases • Requirement: Minimum resources required. High availability, supported for production. • One or more RHEL/CentOS VMs for VMware Cloud Director. External PostgreSQL database (used for VMware Cloud Director and VMware Cloud Director Object Storage Extension). NFS transfer share is needed when more than one VMware Cloud Director cell is used. Protected with vSphere HA. • One CentOS Linux 7 or 8/RedHat Enterprise Linux 7/Oracle Linux 7/Ubuntu 18+/Photon 3+/Debian 10+ VM: (4 vCPU, 8 GB RAM, 120 GB HDD) running VMware Cloud Director Object Storage Extension. Protected with vSphere HA. • vSphere/NSX: As required for VMware Cloud Director resources. • Storage provider: Three CentOS virtual machines running Cloudian HyperStore, or Five CentOS virtual machines running Dell EMC ECS (4 vCPUs, 32 GB RAM, 32+100 GB HDD on shared storage) or AWS S3. • Load balancing: VMware Cloud Director cells and Cloudian HyperStore or Dell EMC ECS nodes load balancing provided by NSX.
Medium Deployment #
Usage: typical use cases • Requirement: High availability, supported for production. • Multiple RHEL/CentOS or appliance VMs for VMware Cloud Director. NFS transfer share. For non-appliance form factor external PostgreSQL database. • One or more CentOS Linux 7 or 8/RedHat Enterprise Linux 7/Oracle Linux 7/Ubuntu 18+/Photon 3+/Debian 10+ VMs: (8 vCPU, 8 GB RAM, 120 GB HDD) running VMware Cloud Director Object Storage Extension. Protected with vSphere HA and optionally load balanced. If VMware Cloud Director is deployed in appliance form factor, an external PostgreSQL database is needed. • vSphere/NSX: As required for VMware Cloud Director resources. • Storage provider: Three CentOS virtual machines running Cloudian HyperStore, Five CentOS virtual machines running Dell EMC ECS on dedicated ESXi hosts with local disks (8 vCPUs, 64 GB RAM, 32 GB HDD + multiple large local disks) or AWS S3. • Load balancing: VMware Cloud Director cells and Cloudian HyperStore, or Dell EMC ECS nodes load balancing provided by NSX or external hardware load balancer.
Large Deployment #
Usage: large scale, low cost per GB use cases • Requirement: High scale, performance, and availability, supported for production. • Multiple RHEL/CentOS or appliance VMs for VMware Cloud Director. NFS transfer share. For non-appliance form factor external PostgreSQL database. • Multiple CentOS Linux 7 or 8/RedHat Enterprise Linux 7/Oracle Linux 7/Ubuntu 18+/Photon 3+/Debian 10+ VMs (12 vCPU, 12 GB RAM, 120 GB HDD) running VMware Cloud Director Object Storage Extension. If VMware Cloud Director is deployed in an appliance form factor, an external HA PostgreSQL database is needed. • vSphere/NSX: As required for VMware Cloud Director resources. • Storage provider: Three or more dedicated bare-metal physical Cloudian HyperStore, Five or more physical Dell EMC ECS, or AWS S3. • Load balancing: an external hardware load balancer
Multi-site Deployment #
Object Storage Extension supports VMware Cloud Director multisite deployments where different VMware Cloud Director instances are federated (associated) with a trust relationship. As these instances can be deployed in different locations, the end-users can deploy their applications with a higher level of resiliency and not be impacted by local datacenter outages.
Each VMware Cloud Director instance has its own VMware Cloud Director Object Storage Extension, which communicates with shared S3 object storage deployed in a multi-datacenter configuration. Objects are automatically replicated across all data centers, and VMware Cloud Director users can access them through either VMware Cloud Director or VMware Cloud Director Object Storage Extension endpoint.

Within a multisite architecture, you can configure VMware Cloud Director Object Storage Extension instances with a standalone virtual data center in each site. The following diagram illustrates the architecture.

When you configure the multisite feature, you create a cluster of multiple VMware Cloud Director Object Storage Extension instances to create an availability zone. You can group the VMware Cloud Director Object Storage Extension instances together only in a single region. A region is a collection of the compute resources in a geographic area. Regions are isolated and independent of one another. VMware Cloud Director Object Storage Extension does not support multi-region architectures.
You can share the same buckets and objects across tenant organizations within a multisite environment. To share buckets and objects across sites, map all tenant organizations to the same storage group. See Edit Tenant Mapping Configuration.
Configuration #
OSE Scalability #
OSE can be deployed as a cluster for high availability and distribution of hardware resources. In the typical deployment topology, there are multiple OSE instances, multiple storage platform instances, and the database HA.
Deploying an OSE Cluster #
Taking Cloudian HyperStore as an example, the steps to deploy the OSE cluster are described below. Procedure
- Prepare the OSE hosts.
- Install the OSE rpm/deb package and start the OSE keeper.
- Prepare the PostgreSQL database and check if it is accessible from the OSE hosts.
- Prepare the Cloudian HyperStore nodes.
- Prepare the Cloudian HyperStore load balancer so that it is accessible from the OSE hosts.
Configuring a Single OSE Instance #
Procedure
- Follow these instructions to configure the OSE certificate, database, and Cloud Director UI plugin.
- Configure the connection to the Cloudian HyperStore Admin endpoint via the load balancer. ose cloudian admin set –url hyperstore-lb-admin-url –user admin-user –secret ‘password’
- Configure the connection to the Cloudian HyperStore S3 endpoint via the load balancer. ose cloudian s3 set hyperstore-lb-s3-url
- Configure the connection to Cloudian HyperStore IAM endpoint via the load balancer. ose cloudian iam set hyperstore-lb-iam-url
- Configure the connection to the HyperStore Web Console via the load balancer. ose cloudian console set –url hyperstore-lb-cmc-url –user admin-user –secret cmc-sso-shared-key
- Validate the configuration. ose config validate
- Start OSE. ose service start
- Log in to Cloud Director and launch OSE to check whether it works normally.
Replicating Configuration on OSE Nodes behind a Load Balancer #
Procedure
- Connect to the first OSE host. ssh user@host-ip
- Export the OSE configuration. ose config export –file=“configuration-file-name” –secret=“the password”
- Copy the exported configuration file to the VMs of the other OSE instances.
- SSH connect to the VMs of the other OSE instances and replicate the configuration by importing the configuration file. ose config import –file=“path-to-the-configuration-file” –secret=“the password”
- Restart the OSE keeper to make the configuration effective. systemctl restart voss-keeper
Now the OSE cluster is created. In general, OSE instances are stateless, and all data is persisted in the shared database, so it is possible to add more nodes on demand.
OSE Java Service #
OSE Java service is built with Spring Boot, which offers both administrative and S3 APIs for OSE UI plug-in and S3 API users.
First, the command ose service [start|stop] can launch and shut down the OSE Java service. The dedicated OSE CLI, e.g., ose cloudian admin set, can set basic configuration for the OSE service. The system administrator can also tune the OSE service with many other configurable properties by using the CLI command ose args set. Here are two examples. • To make OSE work in virtual-hosted style for S3 API, use the command: ose args set -k s3.client.path.style.access -v false • For a huge bucket (containing more than one hundred thousand objects), the object count for the bucket is estimated by default for performance consideration. The estimation can be turned off by the command: ose args set -k oss.object.count.estimate -v false As a Java service, the JVM properties can also be set for the OSE instance. In some cases, the storage platform could be in another network that is accessible by OSE through a configured proxy server. The system administrator can set the JVM proxy options for OSE by using the command: ose jvmargs -v “Dhttp.proxyHost=proxy.cloud.com -Dhttp.proxyPort=3128”
PostgreSQL Database #
OSE uses a PostgreSQL database for storing the metadata of its S3 storage-related operations. The recommended hardware requirements for the database are 8 Core CPUs and 12 GB RAM for most OSE deployments. An impact on the database disk usage will have the object count, not the object content size. The more objects you create in the system, the more disk space the database occupies. Many factors determine disk space consumption. Roughly one million objects cost about 0.6GB disk. Database indexes and logs will also consume disk. So, assuming you have one billion objects in an object storage cluster, you need to prepare more than 700GB of disk for the database machine.
There is a table object_info in the OSE database containing rows for each managed object. If OSE handles twenty million objects, the table will have twenty million rows. Querying such a table could be a performance bottleneck if the database machine has limited CPU and memory resources.
Now that we have the estimation for the database disk consumption with object count (about 0.6GB/million objects), it’s recommended to allocate a buffer for the disk size at the beginning.
Public S3 Endpoint #
S3-compliant API has two path formats: • Path-Style Requests. The path pattern for Amazon S3 is https://s3.Region.amazonaws.com/bucket-name/key name, for example, https://s3.us-west-2.amazonaws.com/mybucket/puppy.jpg. • Virtual Hosted-Style Requests. The path pattern for Amazon S3 is https://bucket-name.s3.Region.amazonaws.com/key name, for example https://my-bucket.s3.us-west-2.amazonaws.com/puppy.png. OSE supports both styles of S3 endpoint, but the segment region is not on the S3 URI; assumed your organization’s root FQDN is https://acme.com.
{kind=link}
{kind=link}
Table 2: S3 API Path Formats
| S3 API Path Formats | Description | Examples |
|---|---|---|
| Path Style | The path-style S3 URI has /api/v1/s3 as the root path. |
Any FQDN can work.
By default, OSE S3 API works in path-style. | https://storage.acme.com:443/api/v1/s3/bucket-1/dog.png
{kind=link}
https://storage.acme.com:443/api/v1/s3/bucket-2/cat.png | | Virtual-Hosted Style | The virtual-hosted style S3 URI has s3. on the FQDN.
{kind=link}
FQDN must use prefix s3. and support wildcard subdomains, i.e., s3.acme.com and *.s3.acme.com. | https://bucket-1.s3.acme.com:443/dog.png
{kind=link}
https://bucket-2.s3.acme.com:443/cat.png |
{kind=link}
There are additional steps to make OSE work in a virtual-hosted style.
Procedure
- Run the command to turn off the path style and switch to the virtual-hosted style:
ose args set -k s3.client.path.style.access -v false - Restart the ose service.
ose service restart - Configure wildcard DNS mapping for OSE S3 endpoint, i.e., map all *.s3.acme.com to the OSE load balancer.
- Create a wildcard SSL certificate for the wildcard FQDN, i.e., make a common name as *.s3.acme.com.
OSE Performance Settings #
The following settings can be applied to your OSE deployment to improve its performance.
Logging #
The OSE logging level has an impact on the performance. To improve the performance, do not turn on the DEBUG logging. Besides, every request access is logged by default. It can be turned off as well.
The following examples show how to set the logging level to WARN or turn off logging. After changing the log level or turning it off, you need to restart the OSE service.
• Setting OSE logging level to WARN
ose args set --k logging.level.com.vmware.voss --v WARN
• Turning off OSE logging
ose args set --k server.undertow.accesslog.enabled --v false
• Restarting the OSE service
ose service restart
Tune I/O Thread Count #
By default, the Undertow server creates server I/O threads per CPU cores on the OSE machine. See for reference: http://undertow.io/undertow-docs/undertow-docs-1.2.0/listeners.html.
If needed, you can increase the I/O thread count to gain performance out of I/O. However, the number should not be too high. For example, if OSE has 8 cores with 1 socket for each host, the default I/O threads for OSE is 2 * 8 = 16. You can increase the number to 24 with the command below:
ose args set --k server.undertow.threads.io --v 24
Tune the Worker Thread Count #
The default working thread count of Spring Boot is 8 * I/O threads for the embedded Undertow server. Increasing the working thread count to match the concurrency is recommended to fully utilize the server capacity for a high concurrency workload. ```ose args set –k server.undertow.threads.worker –v 256``
Set Max Connection Count to Storage Platform #
Concurrent connections to storage platform S3 API directly impact the system’s scalability and throughput. By default, the max connection count is 1000.
ose args set --k s3.client.max.connections --v 1000
Set max Connection Count to the PostgreSQL Server #
Concurrent connections to the database directly impact the system’s scalability and throughput. By default, the max connection count is 90.
Note: The below setting is insufficient to increase the concurrency of database connections. You should consider increasing the max connection count on the PostgreSQL side simultaneously. For example, if the PostgreSQL server’s max connection count is 1000, and you have deployed 5 OSE server nodes, then the average connection count to each OSE node should be less than the max connection count divided by the OSE node count, e.g., < 200.
ose args set --k spring.datasource.hikari.maximumPoolSize --v 180
Other settings for the database connection pool can be seen below. For term explanation, please refer to https://github.com/brettwooldridge/HikariCP#configuration-knobs-baby.
ose args set --k spring.datasource.hikari.maxLifetime --v 1800000
ose args set --k spring.datasource.hikari.idleTimeout --v 600000
ose args set --k spring.datasource.hikari.connectionTimeout --v 30000
Set Multipart Request Threshold for Upload
OSE middleware automatically splits the upload content stream into several parts for large objects. Depending on the network performance between the OSE middleware and storage platform, the threshold can be re-configured. The default setting is when the upload object size is over 1 GB, the upload is split, and each part is <= 1GB size.
ose args set --k s3.client.upload.multipart.threshold --v 1073741824
ose args set --k s3.client.upload.multipart.mini-part-size --v 1073741824
ose args set --k s3.client.copy.multipart.threshold --v 1073741824
ose args set --k s3.client.copy.multipart.mini-part-size --v 1073741824
Turn off Tenant Server-side Encryption #
Tenant Server-side Encryption (SSE) is a unique feature of the OSE middleware. This feature can be turned off globally if you don’t need it, which will improve OSE performance.
ose args set --k oss.tenant.sse.enabled --v false
Turn on OSE Virtual-hosted Style S3 Requests #
By default, OSE works with path-style S3 requests. The command below will make OSE work with virtual-hosted style S3 requests.
ose args set -k s3.client.path.style.access -v false
Tune Object Count of Bucket #
OSE has a feature showing tenant users the object count of each bucket. However, for buckets containing over 10 million objects, counting the bucket’s objects will impact the performance.
Object count estimation is adopted for such buckets. The threshold is a hundred thousand objects per bucket. Use the following commands to adjust the threshold or turn off the estimation.
• Changing the object count estimate threshold
oss.object.count.estimate.threshold=100000
• Turning off the object count estimate
ose args set -k oss.object.count.estimate -v false
Set Proxy for OSE
There are cases in which the storage platform is on another network that is accessible by OSE through a proxy server. You can set the JVM proxy options for OSE by using the following command.
ose jvmargs -v "Dhttp.proxyHost=proxy.cloud.com -Dhttp.proxyPort=3128"
Getting Support #
Generate Support Bundle #
OSE has a native CLI for support bundle, which will collect OSE information and logs of a specific period. See an example below:
ose support --start 2020-03-12 --end 2020-05-24
The optional argument --start defines the start time for the logs to be collected. The default value is 2018-01-01.
The optional argument --end defines the end time for the logs to be collected. If not specified, the end date is the current date.